So far, we’ve seen that creating a local queue can be very useful for streamlining the workload and persisting the work throughout process restarts. However, depending on the type of work that you’re doing, this approach could still present some issues: if this work is somehow CPU-intensive you may need to outsource it to a set of external worker processes, further decoupling the job production from the job consumption.
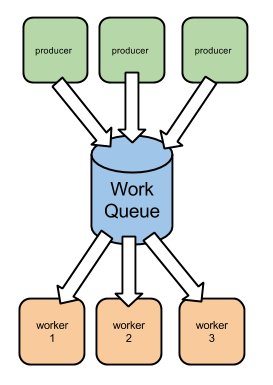
Node.js, and JavaScript in general, are not particularly suited for doing long-running computations. If, for instance, you need to perform number-crunching, the consumers of your queue may not even be in JavaScript, but running on a platform that is more suited to performing such computations.
Even so, you may find out that supposedly simple tasks are somewhat CPU-intensive and deserve a scalability model of their own. For instance, parsing is typically a CPU-intensive operation that is involved in most I/O operations. In this case, even if the application is initially I/O-bound, it may become CPU-bound at scale as more traffic is being generated.
Also, you may want to segregate a specific type of asynchronous work to a set of distinct processes. This allows you not only to isolate dedicated resources, but also to isolate failures: for instance, you don’t want errors in rendering and sending emails to interfere with your HTTP API Server.
In our first example we’ll use Redis as a queue service. Redis is a in-memory store which, amongst many other things, enables you to build a queue service, as we’ll see.
There are some available open-source implementations of a Redis-based queue service in Node.js, and we’ll pick one that was created by yours truly: simple-redis-safe-work-queue. This is a queue implementation on top of Redis that provides just the minimum API for building a distributed producer / worker infrastructure.
As an example, let’s imagine that your server needs to make some client HTTP calls to invoke arbitrary webhooks. First of all, here is the worker code:
worker.js:
We start off by requiring the request module, which is a library for making HTTP calls. Then we require the simple-redis-safe-work-queue module, which we use to create a worker by providing the queue name (invoke webhook) and a worker function (invokeWebhook) to do the actual work.
The worker function has to implement the usual argument signature: it gets the payload as first argument, and a callback function (for when the work terminates or errors) as the second argument. In the body of this function we invoke the request, passing in the webhook options directly and a termination callback we named done.
This callback function gets invoked if there is an error, or if the request finished. Inside this function, we have to parse the response HTTP status code and set an error if it indicates an error. We then call the work callback, passing in the error if one exists.
Retries and idempotency
The worker callback (cb) implements the callback pattern: if it gets an error as the first argument, the work will be retried. If the number of retries exceeds a maximum threshold, the worker will emit a max retries event, passing in the last error and the offending payload. In this case you may choose to escalate the error, which may mean sending it to the error log for a human to pay attention to it.
You can customise the maximum number of retries by providing a maxRetries worker option, which defaults to 10:
In our case, we are invoking a webhook until successful, or until the maximum number of retries is reached. However, in some cases, you may want to perform the operation at most once, independently of whether it fails or not. To do so, you can set maxRetries to 0, and the work unit will not be retried after failure:
Still, you should catch the max retries event to detect permanent failures.
The work producer
We can then create a simple script that pushes a work unit into the queue and then quits:
client.js:
In this specific example we’re also stopping the client right after pushing, which will close the Redis client right after all the pending “pushes” finish. If you’re producing work in the context of a running service, you will want to create the client at boot time and then stop it on shutdown. Here is an example of how you can do this:
Here we’re creating a fictional server listening to port 8080. If an HTTP POST request is made to the /some/important/action URL, we're inserting this document in the database and, if successful, we're pushing some work into the webhook queue. This time we're passing in a callback (pushedWebhookWork), listening to errors and reacting appropriately to them.
Installing some dependencies
Now, in order for this example to work, you need to create a package.json manifest at the root:
package.json:
Once that is in place, instal the missing dependencies locally:
Also, you’ll need a Redis server running.
For information about installing a Redis server in your OS, check out http://redis.io/download.
Once you’ve done that, you can open two terminal windows: one for running a worker and the other one for running the client script.
On the first window, start the worker:
On the second window, run the client:
You should see the worker logging the requested webhooks:
Next article
Redis may be well suited for small enough workloads, but if you need a more scalable and robust messaging platform you can use RabbitMQ.
In the next article I’ll be describing how you can replace this Redis implementation with a RabbitMQ one.
You can find the previous posts on Work Queue Patterns here: