Why is this Node service only handling X requests per second but neither memory, CPU nor network usage is saturated? How does Node handle HTTP connections? Can it process more than one request at the same time for a single non-HTTP/2 connection? If these questions spark your curiosity, read on.
Consider the HTTP hello world example from nodejs.org:
Let’s spin it up (I’m using Node v4.2.6) and run wrk2 — an HTTP benchmarking tool — against it:
This tells wrk2 to try to push a rate of 50000 requests per second (-R) for 15 seconds (-d) using 4 threads (-t) and 20 persistent connections (-c).
I like to do it all in a one-liner:
This starts the Node process, puts it in background, saves the process ID, waits 1 second so that our Node HTTP server can boot up, runs the benckmarking tool against it and finally kills the Node process.
Result:
That’s roughly 14k requests per second (I’ll use the term RPS henceforth).
If you really need to know, I ran this on a late 2013 MacBook Pro Retina with a 2.4 GHz Intel Core i5 and 8 GB 1600 MHz DDR3. The environment will be the same for the rest of the tests.
An HTTP endpoint that replies immediately without doing any I/O probably isn’t a very good representation of how we frequently use Node for HTTP. The hello world example is not what we want to bench. Let’s add a 50 millisecond delay to every response, pretending we’re querying either a database, another service or a file.
How will this affect the benchmark? All we’re doing is just delaying the responses. Node is non-blocking, it can go on and keep processing further requests, right? It just means that these responses get buffered for a bit before being sent out, right?
… No. Wow wait what? How did we go down from 14k to 366 RPS?
What is Node doing? Let’s check the CPU usage. To find out CPU usage I like to run either top, htop or even ps:
When using ps I like to run it with watch so it keeps refreshing and I can just look at it any time:
Running top -pid $(pgrep -o -f "node server") would also work, but I'd have to restart it every time after the node process, with watch + ps I can just leave it running and it picks up the latest Node process which fits nicely with my lazynessHere’s what we find with ps:
- without the delay: CPU usage is really high ~95%
- with the 50ms delay in every response: CPU usage is very low, never above 10%
Maybe we’re capping the amount of work we’re giving Node by having a small number of connections. We can tweak wrk2's parameters to confirm this.
Upping the number of connections to 100 raises the RPS:
And bringing it down to a single connection lowers it even further:
So we’ve determined that the current bottleneck is the number of connections. But there’s no reason our server shouldn’t be able to process more requests, afterall, there’s still CPU, memory, and network bandwidth available. How many connections do we need to make Node use all of it’s host’s resources?In this particular machine 3000 connections seems to top out Node’s CPU usage, and RPS up to 12.5K.
To be able to run this I had to change the operating system’s configuration value for the limit of open files — each open socket means another open file
In a production setup Node is likely sitting behind a load balancer or a reverse proxy. Things like the 3-way-handshake and slow-start are performance costs in the form of extra roundtrips and reduced bandwidth that we need to pay everytime the underlying TCP connection in HTTP requests is established. So keeping connections open — using persistent HTTP connections — is likely something that the balancer will do.
The benchmarking tool we used, wrk2 also makes use of persistent HTTP connections for the same reason, that's why we specify the -c parameter. With this in mind, it's obvious why CPU was low on the second test: wrk2 was waiting on one request to complete before sending out another one. And now that we know that, let's try to make sense of those numbers we got.
Explaining the drop
In our first test we got an average of 14145.13 RPS using 20 connections, that means an average of 707.26 RPS (14145.13 / 20) per connection, or an average of 1.4139 milliseconds per request (1000 / 707.26).
In the second test, we added a 50 millisecond delay, so each request should then take 51.4139 (50 + 1.4139) milliseconds to be served. For a single connection that means 19.45 RPS per connection (1000 / 51.4139), or for all 20 connections, 389 RPS (20 * 19.45).
The numbers we actually hit were 366.90 RPS for 20 connections which is pretty close to 389 RPS, and later with a single connection we hit 18.47 RPS which also is pretty close to 19.45 RPS.
Scaling
Assuming the backend — whatever service or database that’s being used in the request — isn’t a bottleneck, as long as there’s available CPU, available memory and available network bandwidth the number of RPS can be increased with the number of connections.
But what’s the right number of connections for my Node service? In a classical threadpool-based IO-blocking webserver, that number should be close to one per thread. In Node, with non-blocking IO, the answer is, it depends how long your Node service is waiting for IO to complete. The longer the wait, the more connections you need to saturate resources.
In the test we just saw, to saturate a single Node process that adds 50 milliseconds of IO to every request we needed 3k connections. Running on a similar environment but with an 8-CPU host we would want 7 more Node processes to fully leverage all available cores. We would then need 24k connections to saturate all 8 Node processes.
Can we improve this? Is there a way to make Node handle more requests in parallel without having to keep extra connections open?
Enter HTTP pipelining
Persistent connections are achieved by consent of both client and server. HTTP/1.1 assumes every connection is persistent — i.e. both ends should keep the TCP connection open — until one of the parties sends a Connection: close header. But even though the connection is kept open, the client should still wait for the server response before sending in another request.
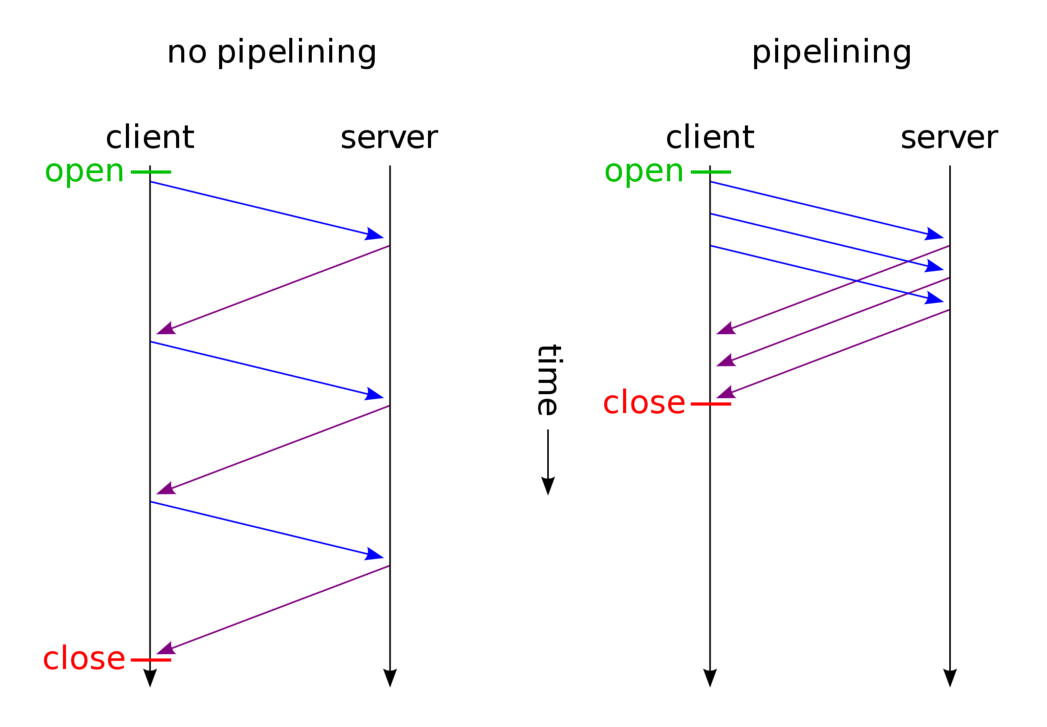
HTTP pipelining is a technique that attempts to improve performance by breaking this rule. If an HTTP client supports pipelining it will go ahead and send several requests on the same connection without waiting for the corresponding responses. The server must also support pipelining and must send back the responses in a FIFO fashion.
If both ends support pipelining, then for each consecutive request you save the equivalent time of an extra roundtrip and if your application is able to process both requests in parallel you save that time as well.
If the server doesn’t support pipelining, or worse, isn’t aware of it, mixed responses can lead to weird and hard to track bugs. That is why most browsers have disabled pipelining. But this doesn’t need to be an issue for our friendly reverse-proxy.
A big concern however with pipelining is head-of-line blocking. A first, slower request, will stall flushing out responses to second faster requests. If the server processes all requests in parallel, the results from all the requests need to wait for the first one to complete so they can be sent back in the same order their respective requests came in. This means more buffering, higher memory usage, and with enough connections and requests it’s easy to make the server run out of memory. In other words, it means a possible DoS attack vector:
- Open and keep alive as many TCP connections as possible
- For each connection, start by sending an HTTP request to a known-to-be slow endpoint
- Without waiting for any server response send as much known-to-be fast requests as possible
This scary problem can be mitigated by:
- limiting the maximum number of simultaneously handled pipelined requests
- setting a timeout for every request and replying with a 408
So again, this might not be much of a concern either.
Does Node support HTTP pipelining?
To test this, we can tweak server.js a bit.
Each request will now take 3 seconds and the response now includes the clock values of when the request started being processed and of when the reply was sent.
Now let’s fabricate a request payload with two requests in a reqs.txt file.
Then spin up server.js and hit it with:
The clock values in both responses indicate that both requests were processed at the same time, and the request id and paths in the responses show that they were sent in the correct order. So Node does indeed handle pipelining correctly. The next question is…
How many requests will Node try to handle at the same time?
Let’s add a counter for the number of parallel requests and monitor it.
Running the same test, our server correctly reports 2 simultaneous requests. Let’s see how high that number goes with wrk2, using a single connection:
Never more than one. This means that wrk2 does not support HTTP pipelining, even though it reuses HTTP connections keeping them open, it waits for a reply before sending in another request.
But we still haven’t reached our answer, how many requests will Node try to handle simultaneously for a single connection? It seems wrk2 is not going to be useful, so we better write our own small script.
This will connect to port 8888 and shove half a million HTTP requests without waiting for any answers. Running against our 50ms delayed endpoint, the server now reports a much larger number of requests being handled simultaneously.
Let’s change server.js again. Instead of a fixed delay let's make it random, that'll be a bit more realistic.
Using our custom client again, this is the kind of logs you get from the server:
Now the number of HTTP requests being handled simultaneously each second varies wildly.
Why is that? What is causing this throttling?
In Node, sockets are streams, and streams have an undocumented 'pause' event. So we could tap into this event on both sides of the connection.
In client.js, we add:
In server.js it gets a bit trickier:
The tagged flag added to the socket prevents registering a handler for the 'pause' event on the same socket object multiple timesRunning client and server again shows that the socket is being paused on the server end, and the stack trace says it’s always coming from the same place:
Digging through the Node.js source code, we can see what’s pausing the stream:
The trigger is either socket._writableState.needDrain or outgoingData >= socket._writableState.highWaterMark. We can confirm which one it is by printing the first value in server.js:
We run it again, check the logs, and all we get is false. That means, unless we have a slow client, the only criteria that's stopping a Node HTTP server from processing more pipelined requests is outgoingData >= socket._writableState.highWaterMark. The outgoingData variable holds the total byte size of the responses that are waiting to be flushed, responses that may be waiting for an earlier and slower request that's causing head-of-line blocking.
We even try and mess with socket._writableState.highWaterMark whose default value is 16kb:
Let’s see how it fares now:
We get higher numbers, but the server gets so flooded with requests that it still can’t answer all of them without any hiccups. CPU usage was maxed out, and after a couple of seconds the process was using 1.4 GBs of memory. This should show how important it is to limit simultaneous requests and having response timeouts when HTTP pipelining is enabled.
Conclusion
What did we learn?
- Node supports HTTP pipelining by default — the only limit is the size of the requests being head-of-line blocked
- HTTP pipelining can be a big benefit but it can also be a big risk if you don’t manage it properly
If you have a Node service in these circumstances:
- sitting behind a load-balancer or a reverse proxy
- service clients are experiencing big latencies/timeouts
- the resources in the hosts running Node aren’t saturated (cpu, mem, net)
- backend services or databases (used by your Node service) aren’t saturated
Then your performance bottleneck is the number of connections between the load-balancer and Node. The available options to improve that bottleneck are:
- increasing the number of connections
- enabling HTTP pipelining, but limiting it to prevent DoS
- moving to HTTP/2
HTTP/2 is able to multiplex different requests through the same connection avoiding head-of-line blocking, so if you’re using it you have the best of both worlds — parallelised request handling and no head-of-line blocking.