This is the first of a series of articles that will be diving into using work queues to manage asynchronous work in Node.js, extracted from the Node Patterns series.
Enjoy!
It is common for applications to have workloads that can be processed asynchronously from application flows. A common example of this is sending an email. For instance, when a new user registers, you may need to send him a confirmation email to validate that the address the user just entered is actually theirs. This involves composing the message from a template; making a request to an email provider; parsing the result; handling any eventual errors that may occur; retrying, etc.. This flow may be too complex, error-prone or take too long to include it in the cycle of an HTTP server. But there is an alternative: instead, we may just insert a document into persistent storage where we describe that there is a pending message to be sent to this particular user. Another process may then pick it up and do the heavy lifting: templating, contacting the server, parsing the errors, and rescheduling the work if necessary.
Also, it is quite common for systems to have to integrate with other systems. I have worked on some projects that require a two-way synchronisation of user profiles between different systems: when a user updates the profile on one system, those changes need to be propagated to the other system, and vice versa. If you don’t require strong consistency between the two systems, where having a small delay between the synchronisation of profile data may just be acceptable, this work can be done asynchronously, by another process.
More generally, it’s a common pattern throughout systems to have a work queue that separates the work producers from the work consumers. The producers insert work into a work queue and the consumers pop work from the queue, performing the required tasks.
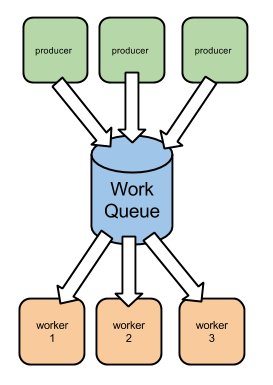
There are many reasons and advantages on using such a topology, such as:
- Decoupling work producers and work consumers
- Making retry logic easier to implement
- Distributing work load throughout time
- Distributing work load throughout space (nodes)
- Making asynchronous work
- Making external systems easier to integrate (eventual consistency)
Let’s analyse some of them.
Isolate
Sending an email is an action that many applications need to do. As an example, when a user changes his password, some applications kindly send an email informing the user that someone (hopefully not someone else) changed the password. Nowadays, sending an email is usually done via a third-party email provider service through a HTTP API call. What happens if this service is slow or unreachable? You don’t want to have to roll back the password change just because an email couldn’t be sent. And surely you don’t want to crash the password-change request because a non-important part of the work involved in processing that request failed. Sending that email is something that can hopefully be done quickly after the password gets changed, but not at this price.
Retry
Also, changing a password may mean that you will have to change the password for that user in two systems: a central user database and a legacy system. (I know, that’s terrible, but I’ve seen this more than once — the real world can be a messy place.) What happens if the first succeeds but the second fails?
In both these cases you want to retry until you succeed: changing the password in the legacy system is an operation that can be repeated many times with the same outcome, and sending an email can be retried many times.
If, for instance, the legacy system manages to change the password but somehow fails to reply successfully, you still may retry later given that the operation is idempotent.
Even non-idempotent operations can benefit from being handled by a work queue. For instance, you can insert a money transaction into the work queue: if you give each money transaction a universal unique identifier the system that will later receive the transaction request can make sure that no duplicate transactions occur.
In this case you mainly have to worry that the work queue provides the necessary persistence guarantees: you want to minimise the risk of losing transactions if systems malfunction.
Distribute and scale
Another reason why you may want to totally decouple work producers from work consumers is that you may need to scale the worker cluster: if the task involved consumes many resources, if it’s CPU-heavy, or needs lots of RAM or other OS resources, you can scale that separately from the rest of your application by putting it behind a work queue.
In any application, some operations are heavier than others. This may introduce disparate work loads throughout nodes: a node that unfortunately handles too many concurrent work-heavy operations may become overburdened while other nodes sit idle. By using a work queue you can minimise this effect by spreading specific work evenly among workers.
Another effect that a work queue can have is to absorb work peaks: you may plan your work cluster for a given maximum capacity and make sure that capacity is never exceeded. If the amount of work rises tremendously for a short period of time, that work will be absorbed by the work queue, isolating the workers from the peak.
Monitoring the system plays an important role here: you should constantly monitor the work-queue length, work latency (the time it takes to complete a work task), the worker occupation, and capacity for deciding on the optimal minimal resources for a satisfactory operation latency during peak time.
Survive crashes
If you don’t need any of the above, a good reason to have a persistent work queue is to survive crashes. Even if an in-memory queue on the same process would fit your application needs, persisting that queue makes your application more resilient to process restarts.
But enough about theory — let’s jump into implementation.
The Simplest Case: an In-Memory Work Queue
The simplest work queue you can devise in Node.js is an in-memory queue. Implementing an in-memory queue here would be an academic exercise (which I can leave to the reader). Here we’ll be using Async’s queue primitive to build a work queue.
Let’s imagine that you’re building this domotic application that interfaces with a hardware unit that controls your house. Your Node.js application talks to this unit using a serial port, and the wire protocol only accepts one pending command at a time.
This protocol can be encapsulated inside this domotic.js module that exports three functions:
.connect()- to connect to the domotic module.command()- to send a command and wait for the response.disconnect()- to disconnect from the module
Here is a simulation of such a module:
domotic.js:
Notice here that we’re not interacting with any domotic module; we’re simply faking it, calling the callbacks with success after 100 milliseconds.
Also, the.commandfunction simulates connection errors: ifsucceeds()returnsfalse, the command fails with a connection error with a probability of 50% (our domotic serial connection is very error-prone). This allows us to test if our application is successfully reconnecting and retrying the command after such a connection failure.
We can then create another module that can issue commands behind a queue:
domotic_queue.js:
There is a lot going on here — let’s analyise it by pieces:
Here we’re importing some packages:
async- which will provide us with the memory-queue implementation;backoff- which will allow us to increase the intervals after each failed attempt to reconnect;./domotic- our domotic simulator module.
We start our module in the disconnected state:
var connected = false;
We create our async queue:
var queue = async.queue(work, 1);
Here we’re providing a worker function named work (defined further down in the code) and a maximum concurrency of 1. Since we have defined that our domotic module protocol only allows for one outstanding command at a time, we're enforcing that here.
We then define the worker function that will process the queue items, one at a time:
When our async queue chooses to pop another work item, it calls our work function, passing in the work item and a callback for for us to call when the work is finished.
For each work item, we’re making sure we’re connected. Once we are connected, we use the domotic module to issue the command, using the command and options attributes that we know will be present in the work item. As a last argument we pass a callback function that we conveniently named callback, which will be called once the command succeeds or fails.
On the callback we’re explicitly handling the connection error case by setting the connected state to false and calling work again, which will retry the reconnection.
If, instead, no error happens, we have the current work item terminated by calling the work callback cb.
Our ensureConnected function is then responsible for either invoking the callback if we're on the connected state, or trying to connect otherwise. When trying to connect, we use the backoff module to increase the interval between each re-connection attempt. Every time the domotic.connect function calls back with an error, we back off, which increases the interval before triggering the backoff event. When the backoff event triggers we try to connect. Once we successfully connect we invoke the cbcallback; otherwise, we keep retrying.
This module exports a .command function:
This command simply compiles a work item and pushes it to the queue.
Finally, this module also exports a .disconnect function:
Here we’re basically making sure that the queue is empty before calling the disconnect method on our domotic module. If the queue is not empty, we wait for it to drain before actually disconnecting.
Optionally, in the case where the queue is not yet drained, you could set a timeout, enforcing the disconnect after that.
We can then create a domotic client:
client.js:
Here we’re pushing 20 settime commands to our domotic module in parallel, also passing in a callback that will be called once each command is finished. If one of those commands errors, we simply handle it by throwing and interrupting execution.
Right after pushing all commands we immediately disconnect, but hopefully our module will wait until all the commands have been executed before actually disconnecting.
Let’s try it from the command line:
Here we can see that all the commands are immediately pushed into the queue, and that the commands finish in sequence, separated by a random period of time. Finally, after all the commands are completed, the disconnection occurs.
Next article
In the next article of this series we’ll be looking at how we can survive process crashes and limit memory impact by persisting the work items.
This article was extracted from the Work Queues book, a book from the Node Patterns series.